

How the Modern Data Stack helps commercial teams to overperform

For the last decade, it's been common knowledge that data-driven commercial ops (sales, marketing, CS) are the most effective way to push your revenue to the next level. And in the last few years, the way that businesses have achieved this has been revolutionized by the modern data stack.
Modern data stacks not only enable commercial teams to meet their goals with greater ease, but exceed them as well.
In this article, we're going to take a look at how this can be achieved by using modern data tools and strategies.
What is a modern data stack?
First and foremost, let's start with a consensus on what makes a data stack "modern". Data stacks themselves are not all that new. Since the internet boom in the early 2000s, businesses have been building databases and using those databases to inform all facets of their operation.
Typically, these "traditional" data stacks have worked by stringing various data collection services, data storage platforms, and data transformation applications together. A marketing app collects data, which is stored in a spreadsheet, and then an analyst uses a transformation app to pull value from that stored data.
The problem with this traditional approach is that it's far too narrow to work in a modern context. Most businesses have multiple channels for collecting data as well as far more data than an analyst and an app can sift through. And this outdated way of stringing services together with APIs and custom scripts can quickly become a spaghetti mess of code.
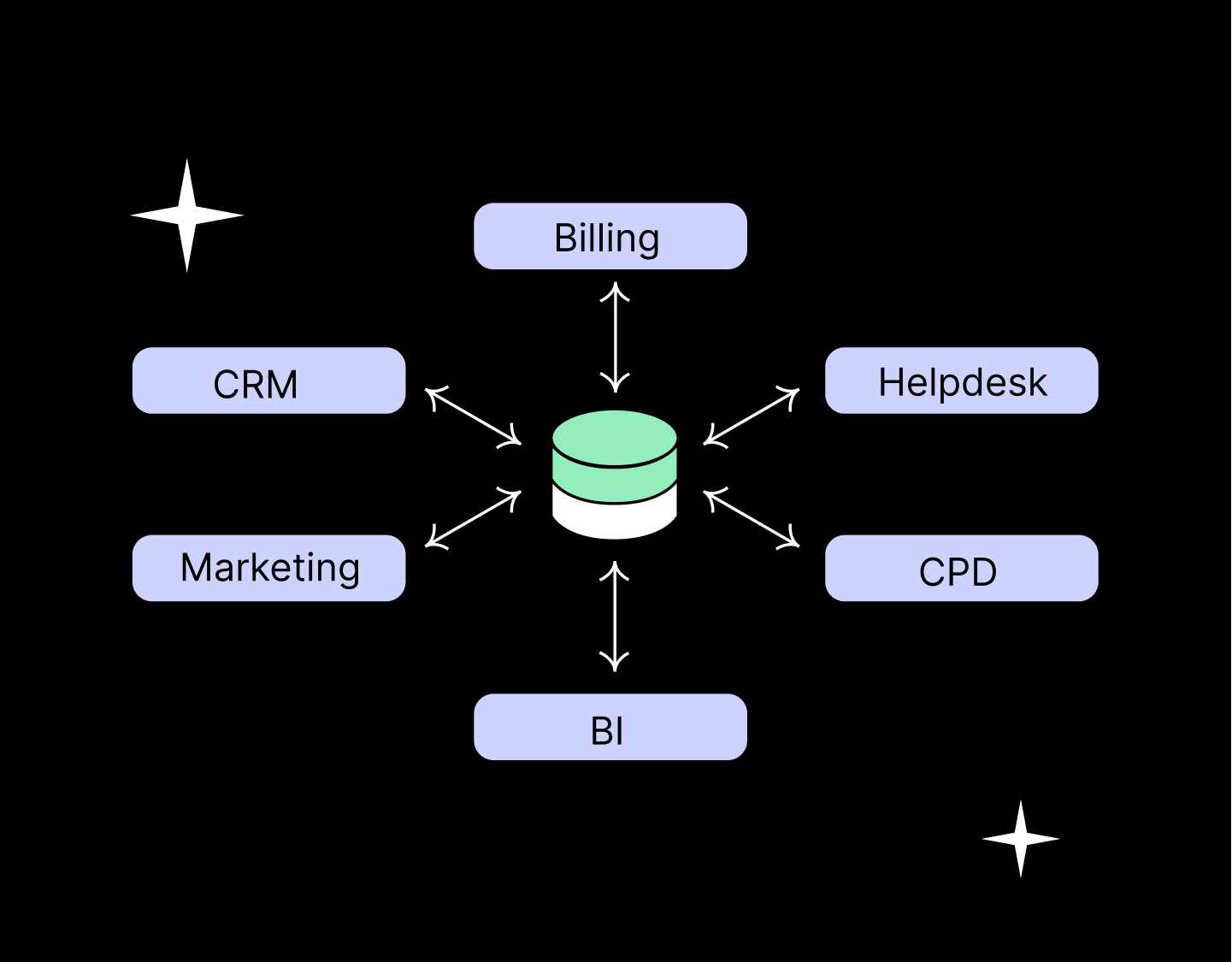
That's where modern data stacks come in. They replace your database(s) with a single data warehouse like Snowflake, BigQuery or Redshift. All of your data from all of your various data intake sources is stored in this warehouse. Your data is also transformed here and is afterward sent out to whatever applications and SaaS services your team uses. It's far more organized, reliable, and scalable.
Why having a modern data stack is important
In today's world, most organizations already have a solid idea of why a data stack is valuable. Data is critical in making your service more personal, increasing the effectiveness of your marketing, and ensuring that the risks you take are more likely to result in high ROI.
The reason a modern data stack is important is that it meets the moment. As covered, traditional data stacks are becoming less and less effective due to the amount of data being collected and the number of sources and outlets through which data is being piped.
The inability of traditional data stacks to meet this demand means that businesses are investing a lot of resources into collecting data without seeing the full value of that data being capitalized on. To keep up with prevailing trends and stay competitive, a modern data stack is a must.
How the modern data stack helps commercial teams over-perform
The beauty of the modern data stack isn't just that it allows you to keep up with the competition. For most commercial teams, it will do far more than that. You'll be over-performing in several areas, changing what you previously thought was within your organization's capabilities.
To put this into perspective, here are several ways in which a modern data stack isn't just the next big thing – it's a revolutionary tool for work.
It allows you to activate your data with a reverse-ETL
In a traditional context, we look at data through an analytical lens. We say, "Ok, there's something to this data that we can learn from - how can we uncover that value?"
This is not the way we look at data through a modern data stack lens. Instead, we are looking to activate data. It's operational – not merely analytical.
To get a better idea of what this looks like, here is a quick compare-contrast of the old way of viewing data versus this new "activated" way.
What data activation looks like without a modern data stack
Let's say you're a customer support team member. Your manager has decided that you're now going to be prioritizing support tickets based on churn risk rather than the chronological order that those tickets come in.
Your organization has a handful of apps and services in place that contain various points of data to give you an idea of how likely a customer is to churn. After checking each data point, you calculate or estimate this customer's likelihood of churning, compare it to other customers' scores, and then prioritize who you're going to respond to that day accordingly.
In a sense, this approach is better for your organization, though it requires more legwork, tedium, and introduces new points for errors to take place.
Here's what it looks like with a modern data stack
In a modern data stack where your data is activated, not just analyzed, this legwork is done for you. There is transformative software in your data warehouse, which has already collected all of the data points from the various SaaS apps you need to determine how likely a customer is to churn. Additionally, the calculated churn risk model lives in your data warehouse and is continuously kept up-to-date, automatically.
So instead, you show up to work and are presented with an automatically-generated list of tickets and the order in which they should be responded to. It's faster, more accurate, and less menial. You're able to help more customers while experiencing less mental taxation.
This is just one example out of countless examples of how data activation can revolutionize various operations throughout your business. You can learn more about this specific example and others in this post.
What to look for in a reverse-ETL
There are a lot of things you'll want to consider when choosing a reverse-ETL (i.e., a data activation service). Here are some of the key points to consider.
First, it's crucial that a reverse-ETL syncs reliably. This is the most critical point, as inconsistent syncing can lead to faulty data and inaccurate results.
Second, having a high number of connections and integrations with apps is also key. It will ensure that you're able to scale with this solution, regardless of the services and workflows you adopt over the years.
It creates a single source of truth in your data warehouse
Data silos, which most companies and departments today are having to deal with, can create conflict and disorder when it comes to your data. That's because no one has access to the same data, and there's no consensus on which data is "correct".
With a data warehouse, this issue is completely removed. It acts as a single point of truth for your entire organization, ensuring that everyone not only has access to the same data but knows that the data they are accessing is wholly trustworthy. Each person can act faster and with increased confidence.
Manually building and maintaining data pipelines is no longer necessary
Another way that a modern data stack can enable your commercial team to over-perform is by removing the need to manually manage data pipelines. Modern data stacks like Weld allow you to view, model, and activate your data without needing to write scripts or APIs.
With a traditional data stack, you would need to spend weeks crafting your code and integrations. A modern data stack, on the other hand, allows you to connect to a new data source/output in minutes.
Make data-driven sales your staple strategy with Weld's modern data stack solutions
The modern data stack approach is the way of the future. If you're ready to start investing in a more effective, affordable, and long-term approach, reach out to the team at Weld today for a free demo. We can revolutionize the way you collect and distribute your data as well as provide expert insights on data warehousing.
Continue reading
.jpg&w=1200&q=75)
New Destination Alert: PostgreSQL
You can now effortlessly sync your data from over 150 sources directly into your PostgreSQL database. Get ready to supercharge your data management an


Navigating Data Differences Between Weld and Google Analytics 4
Navigating Data Differences Between Weld and Google Analytics 4. A look into the reasons behind the data discrepancies you might encoun

.png&w=1200&q=75)
New feature Alert: Sync History Insights Chart
Finding and sorting data sources, as well as seeing a historical overview of your syncs, is now easier than ever




